はじめに
近年、画像を分析してそこから情報やインサイトを抽出することが一般的になってきています。画像の分析は高度な知識が必要ですが、Amazon Rekognition を使うことによって簡単に画像を分析することができるので本エントリーで試してみようと思います。
Amazon Rekognition とは
画像や動画を分析するサービスです。有名人を検出したり表情から感情を分析したりすることができます。Amazon Rekognition には以下2つサービスがあり、本エントリーでは「Amazon Rekognition Image」を使います。
Amazon Rekognition が提供する機能
本エントリーでは Amazon Rekognition Image の「ラベル検出」を使います。

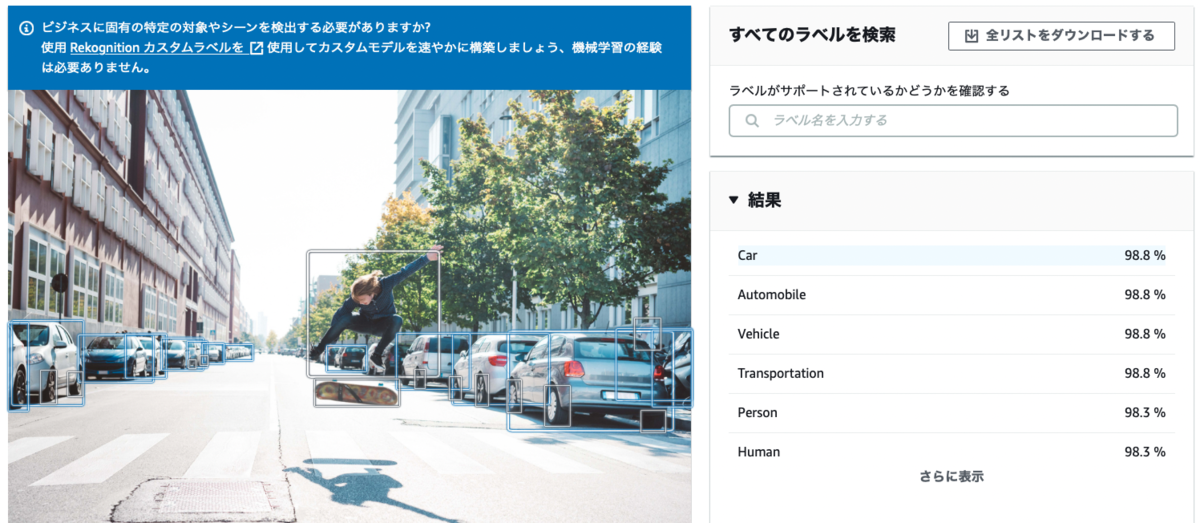
例えば、ラベル検出を以下の画像に対して実行すると、画像内の「車」「自動車」「人」などがラベルとして検出されて、それぞれの信頼度がパーセンテージで表示されます。
アーキテクチャ
S3 にアップロードした画像の分析を行い、結果を DynamoDB に保存します。
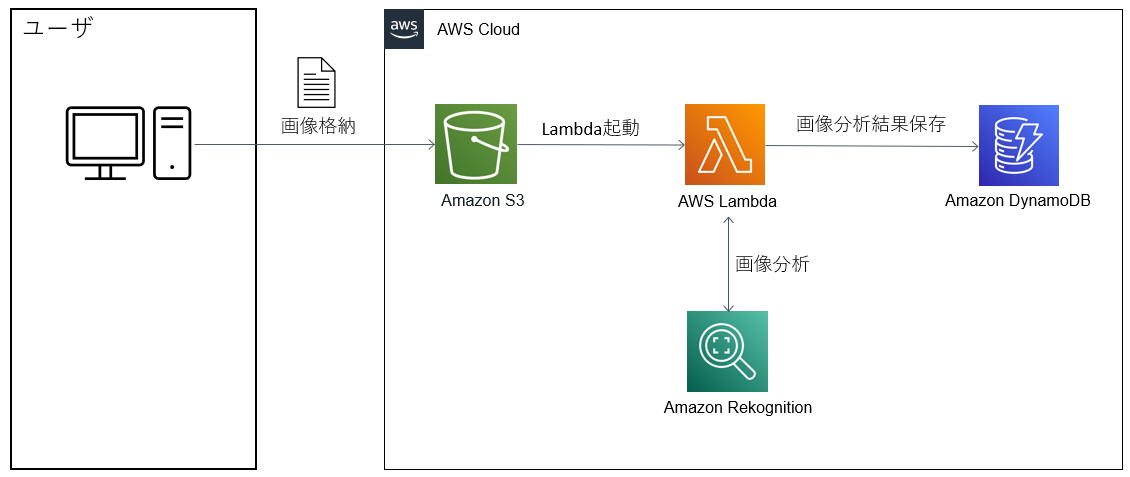
役割
| サービス名 | 内容 |
|---|---|
| Amazon S3 | 画像ファイルの格納を Lambda に通知 |
| AWS Lambda | Amazon Rekognition の実行と分析結果の DynamoDB への格納 |
| Amazon Rekognition | 画像分析の実行 |
| Amazon DynamoDB | 画像分析結果の格納 |
手順
1. S3 バケットの作成
「20220812-rekognition-test」バケットを作成します。
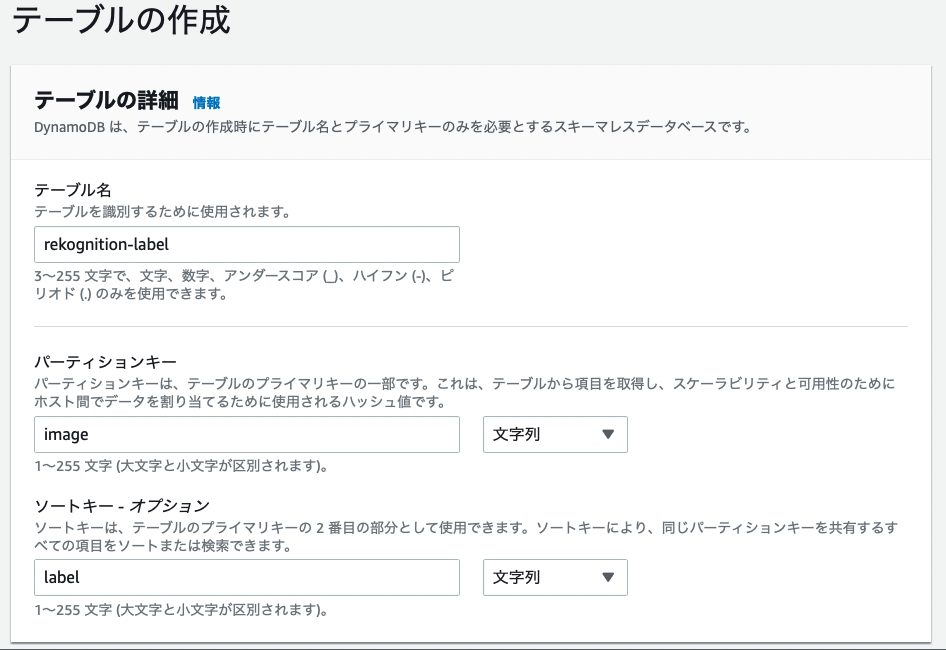
2. DynamoDB テーブルの作成
検出したラベルを保存する DynamoDB のテーブルを作成します。
[テーブル名]:rekognition-label
[パーティションキー]:image
[ソートキー]:label
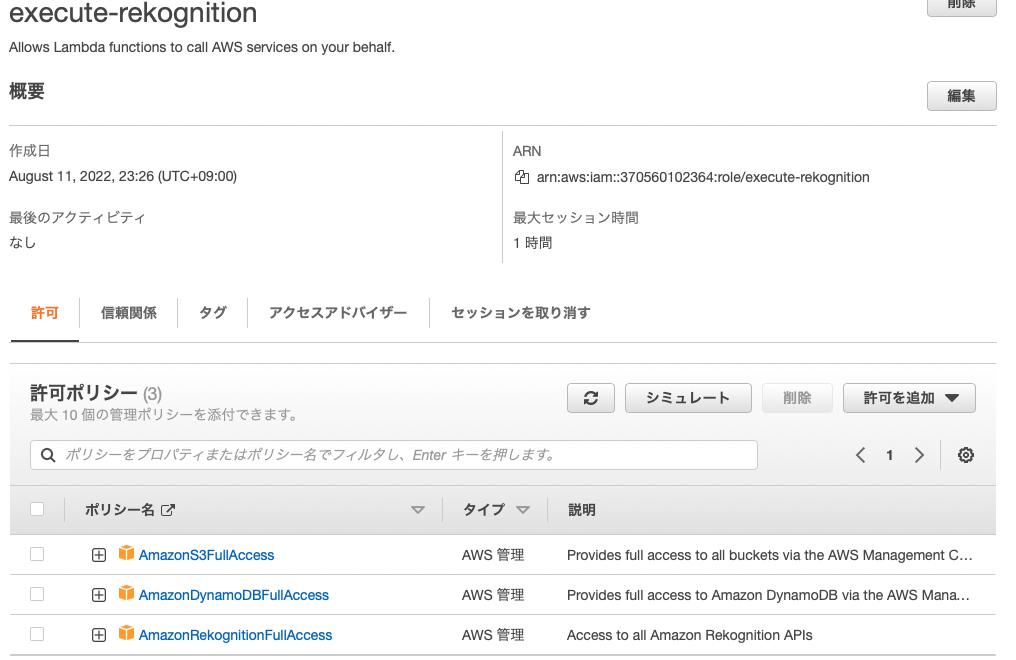
3. IAM ロールの作成
S3、Rekognition、DynamoDBへの権限を付与したロールを作成します。
4. Lambda 関数の作成
以下のように Lambda 関数を作成します。
[オプション]:一から作成
[アーキテクチャ]:x86_64
[関数名]:rekognitionFunction
[ランタイム]:Python 3.9
[既存のロール]:execute-rekognition
コード
Amazon Rekognition の実行と分析結果を DynamoDB へ格納する Lambda 関数のコードです。
import json import urllib import boto3 # 使用するサービス s3 = boto3.client('s3') rekognition = boto3.client('rekognition') dynamodb = boto3.resource('dynamodb') # DynamoDB テーブル table = dynamodb.Table('rekognition-label') def lambda_handler(event, context): # バケット名取得 bucket = event['Records'][0]['s3']['bucket']['name'] # オブジェクト名取得 key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') # ラベル検出の実行 detect = rekognition.detect_labels( Image={ 'S3Object': { 'Bucket': bucket, 'Name': key } } ) # ラベルを取得 labels = detect['Labels'] for i in range(len(labels)): label_name = labels[i]['Name'] label_confidence = int(labels[i]['Confidence']) # 信頼度が80%以上のラベルのみDynamoDBに保存する if label_confidence >= 80: table.put_item( Item={ 'image': key, 'label': label_name, 'confidence': label_confidence, } )
5. S3 バケットへのイベント通知の作成
作成方法については以下のエントリーをご参照ください。
6. 動作確認
使用する画像
こちらの画像を使用します。

処理実行
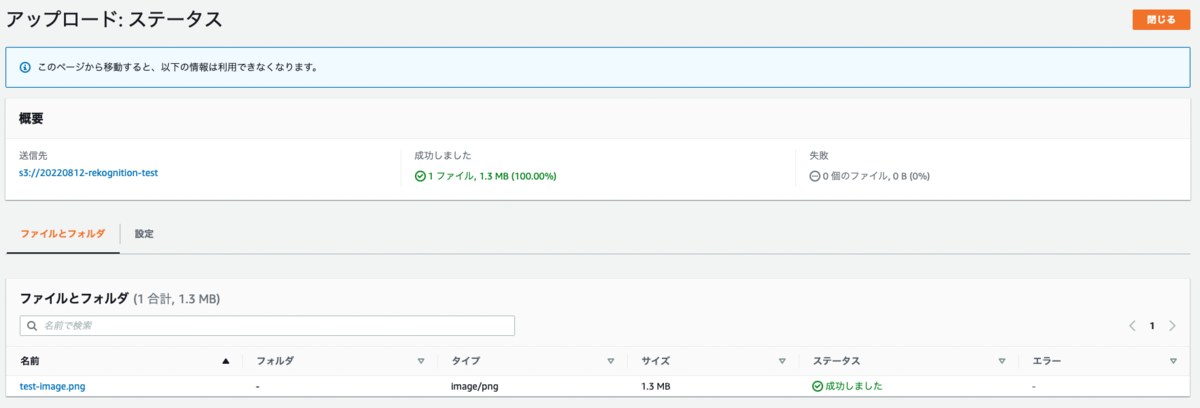
S3 バケットに上記の画像をアップロードします。
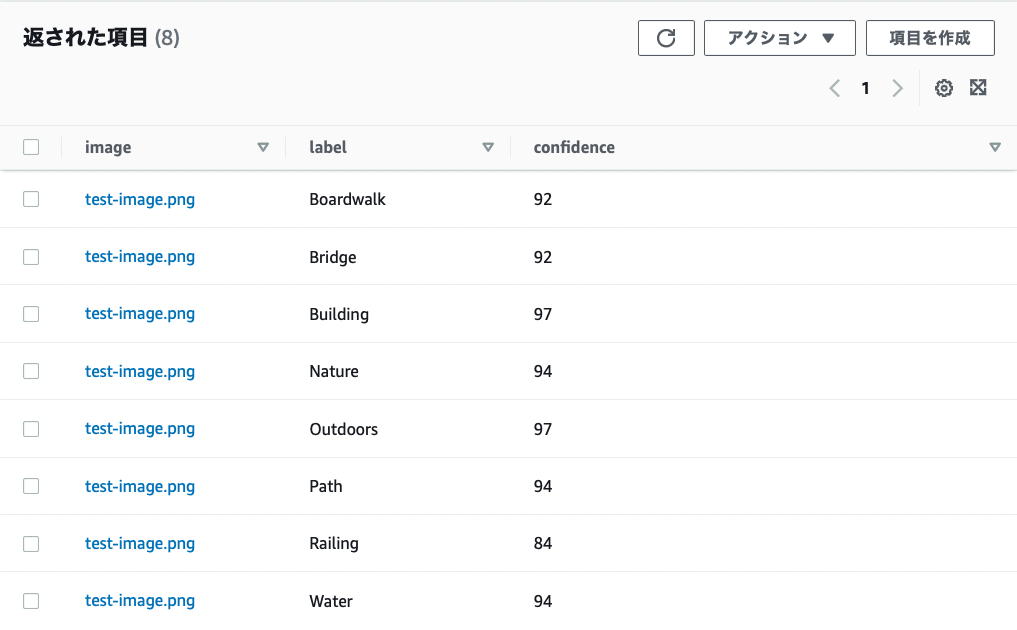
DynamoDBにラベルが格納されたことを確認します。Boardwalk や Building など写真にある物体を認識していることがわかります。
さいごに
Amazon Rekognition を使えばさくっと画像分析の実行が可能ということがわかりました。今後は Amazon Rekognition Video を使って動画の分析もやってみようと思います。