はじめに
前回のエントリーで S3 と SQS の連携を試してみました。本エントリーはその続きで SQS キューに S3 から通知がきた後に SQS キューのメッセージを Lambda で処理してみようと思います。
使用するサービス
- Amazon S3・・・AWS が提供するオブジェクトストレージサービス
- Amazon SQS・・・フルマネージド型のメッセージキューイングサービス
- AWS Lambda・・・サーバーをプロビジョニングしたり管理しなくてもコードを実行できるコンピューティングサービス
アーキテクチャ

役割
- Amazon S3・・・アップロードするファイルを格納
- Amazon SQS・・・ S3 にアップロードされたファイルの情報を Lambda に送信
- AWS Lambda・・・SQS から送信されたファイル情報をもとにファイルの名前を変えて S3 に同じファイルをアップロード
手順
- IAMロールを作成
- S3 バケットを作成
- SQS キュー を作成
- Lambda 関数を作成
- 動作確認
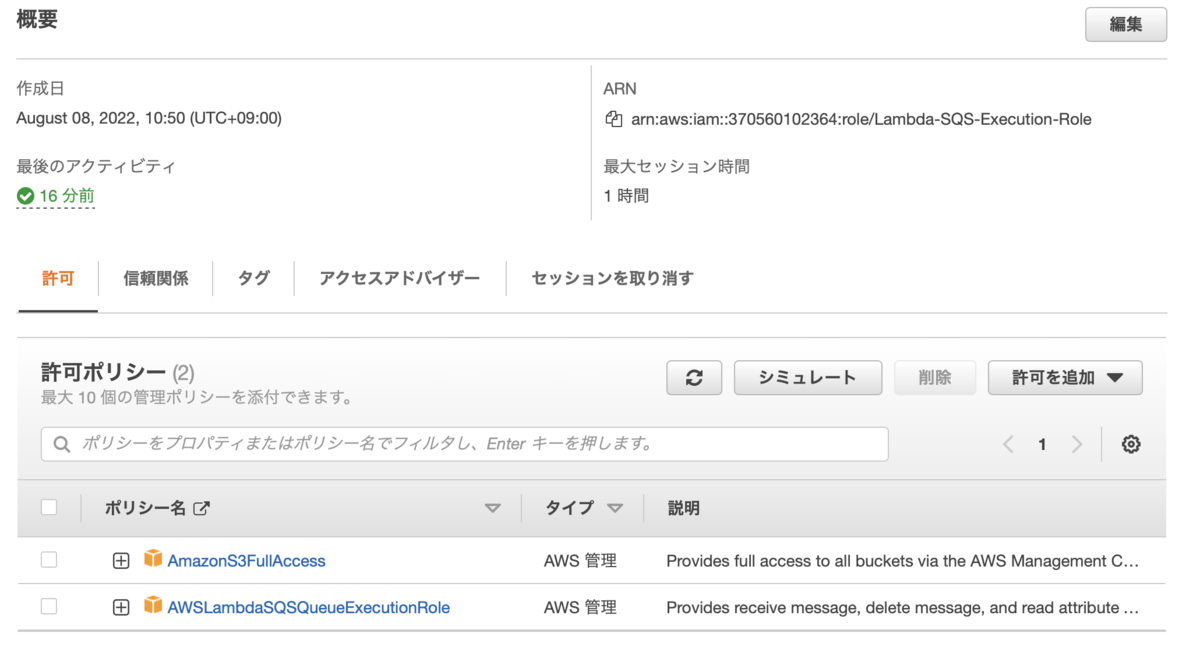
1. IAMロールを作成
「Lambda-SQS-Execution-Role」という名前のLambda に SQS と S3 に対する実行権限を付与するロールを作成します。
2. S3 バケットを作成
前回のエントリーを参照してください。
3. SQS キュー を作成
前回のエントリーを参照してください。
4. Lambda 関数を作成
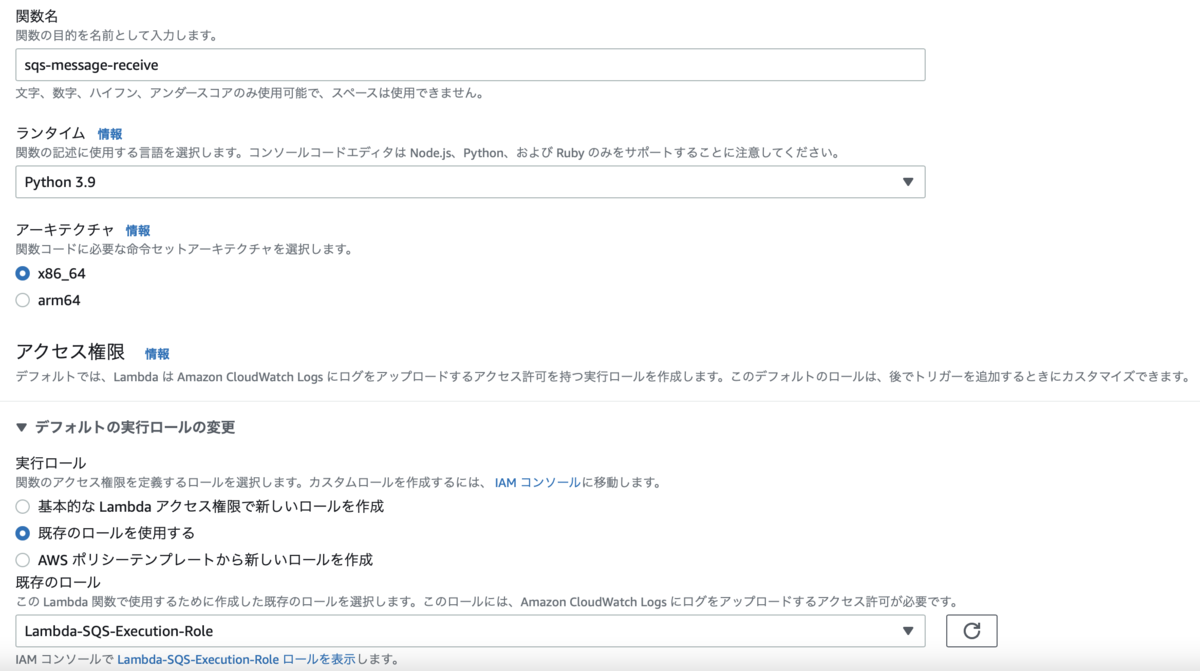
SQS キューのメッセージを処理するLambda関数を作成します。
[関数名]:sqs-message-receive
[ランタイム]:Python 3.9
[実行ロール]:Lambda-SQS-Execution-Role
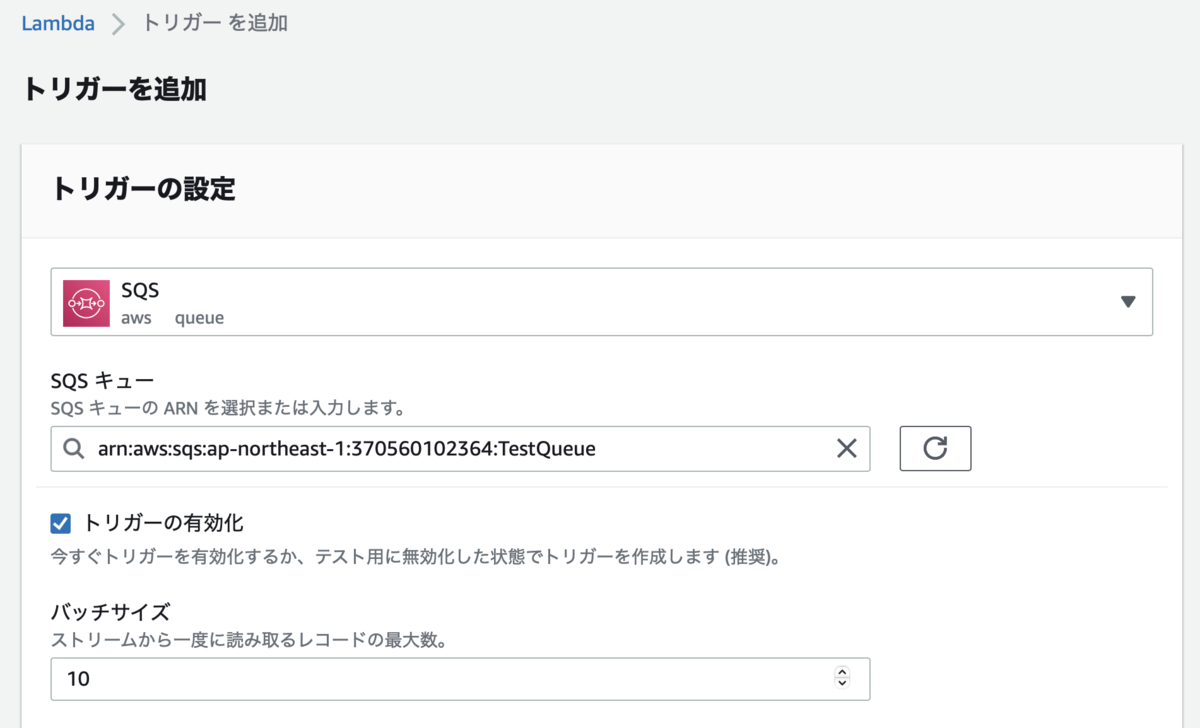
SQS キューをトリガーとして追加します。
ソースコード
S3 バケットにアップロードしたファイルの名前を変えて同じバケットにアップロードするプログラムです。
import json import os import urllib.parse import boto3 import subprocess from datetime import datetime def lambda_handler(event, context): s3 = boto3.resource('s3') # バケット名取得 bucket_name = event['Records'][0]['s3']['bucket']['name'] # バケット取得 bucket = s3.Bucket(bucket_name) # アップロードしたファイル名を取得 key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') # Lambdaのローカルのファイル保存先(/tmp)を設定 file_path = '/tmp/' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') try: # /tmpにダウンロード用のフォルダを作成 cmd = ['mkdir', '-p', file_path] subprocess.run(cmd, stdout=subprocess.PIPE) # S3に格納したファイルを作成したフォルダにダウンロード bucket.download_file(key, os.path.join(file_path, key)) # ファイルの名前を変えてS3にPUT bucket.upload_file(os.path.join(file_path, key), 'hane2.jpg') return except Exception as e: print(e)
5. 動作確認
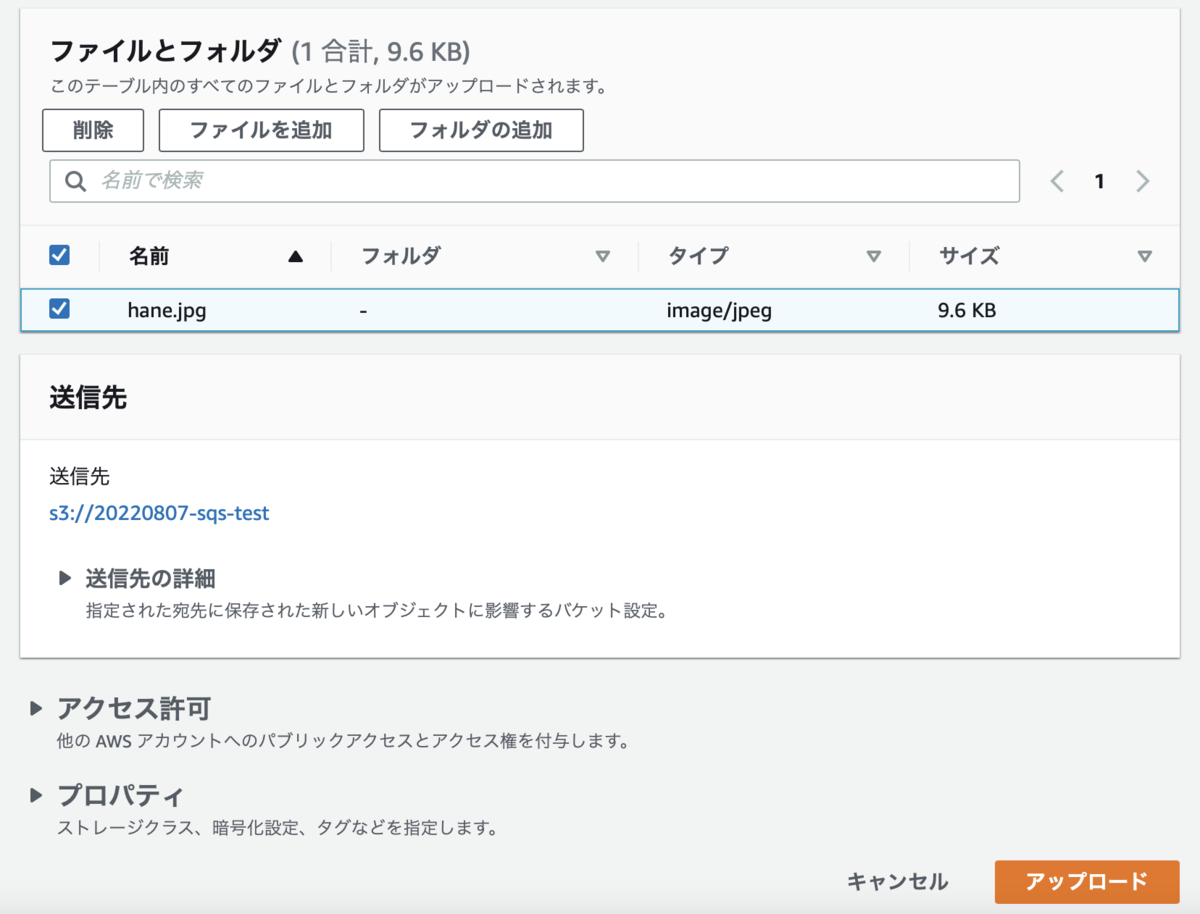
hane.jpg をアップロードします。
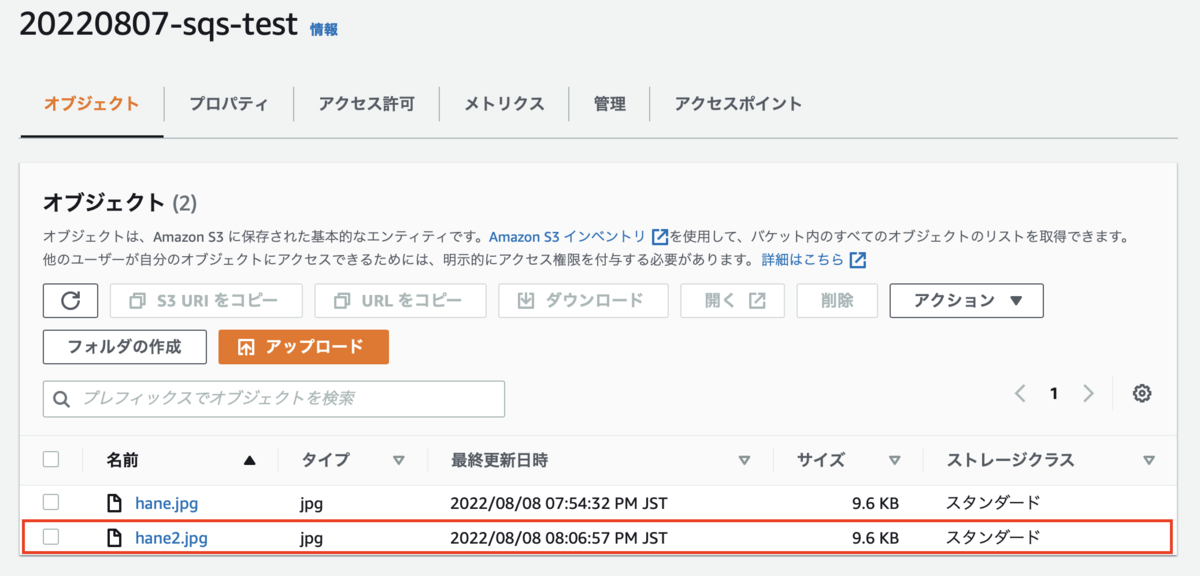
Lambdaによってhane2.jpg がバケットに作成されました。
さいごに
今回は簡単な処理だけだったので SQS を使う必要はないと思いますが、SQS と Lambda を実際にどのように連携するかを理解するためのいい勉強になりました。今度はデッドレターキューなど SQS をフルに活用できる構成を試してみたいですね。