はじめに
以前のエントリーでSQS キューのメッセージを Lambda で処理してみましたが、今回は EC2 を使ってみようと思います。
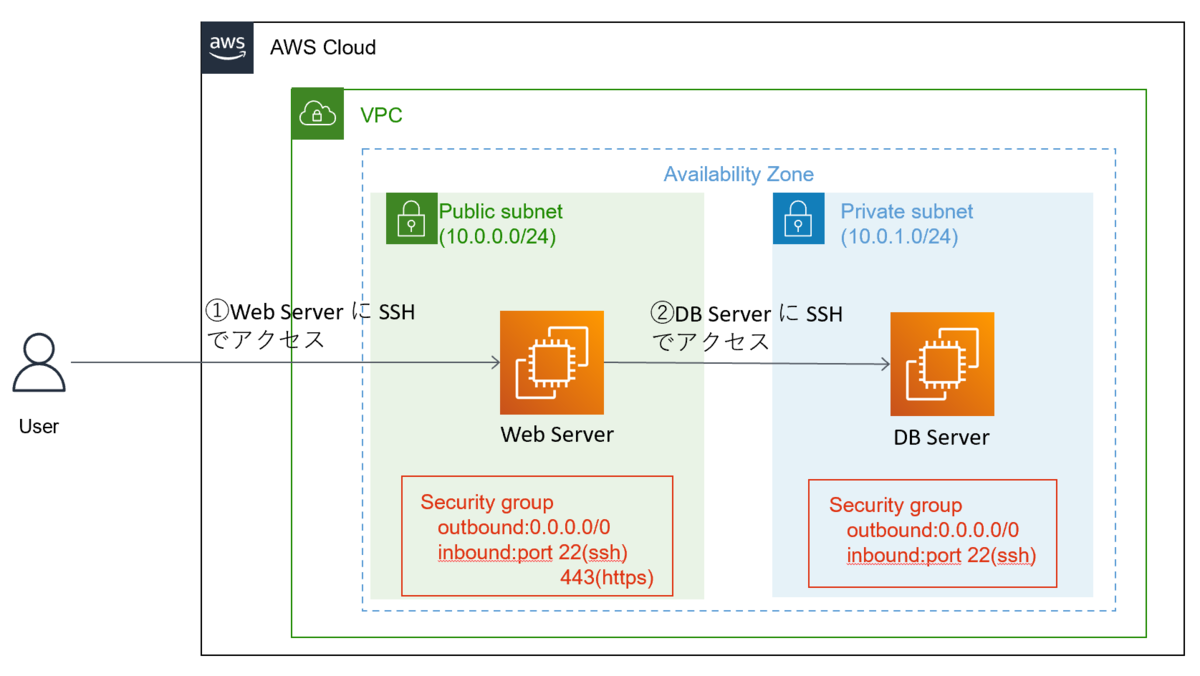
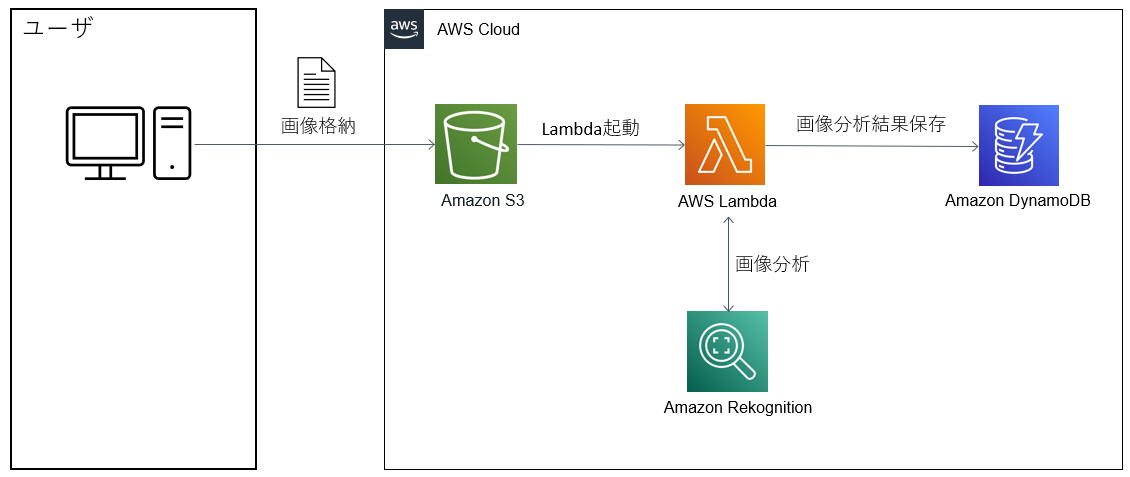
アーキテクチャ

アプリケーション間連携に SQS を使うケースはこんな感じのアーキテクチャになるのではないでしょうか(その場合 EC2 の数はもっと多いかと思いますが)。
手順
- インスタンス構築
- SQS キュー を作成
- EC2 で SQS にメッセージを送信する処理の作成
- EC2 でメッセージを SQS から受信する処理の作成
- 動作確認
1. インスタンス構築
以下二つのインスタンスを構築します。
| ホスト名 | OS | 用途 |
|---|---|---|
| producer-server | Amazon Linux 2 | SQS にメッセージを送信する |
| consumer-server | Amazon Linux 2 | SQS からメッセージを受信する |
Python3系 のインストール
list installed を実行して、Python 3 がホストにすでにインストールされているかどうかを確認します。
yum list installed | grep -i python3
Python 3 がまだインストールされていない場合は、yum パッケージマネージャーを使用してパッケージをインストールします。
sudo yum install python3 -y
boto3 をインストール
仮想環境をアクティブにして、boto3 をインストールします。
#仮想環境の構築 python3 -m venv my_app/env #仮想環境をアクティブにする source ~/my_app/env/bin/activate #boto3をインストール pip install boto3
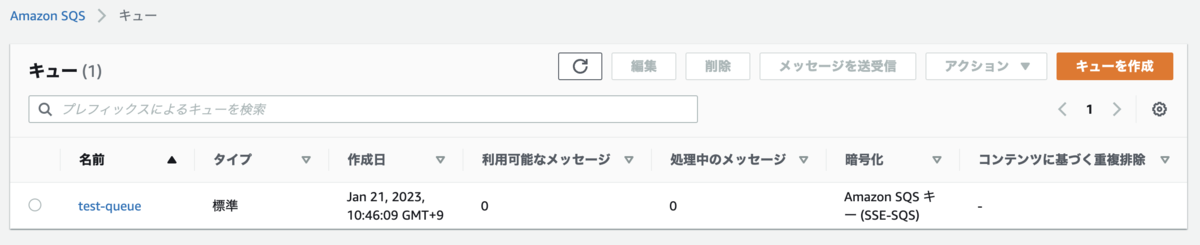
2. SQS キュー を作成
test-queue という名称のキューを作成します。設定はデフォルトでOKです。
3. EC2 で SQS にメッセージを送信する処理の作成
SQS へメッセージを送信する処理です。
import json import boto3 sqs = boto3.client("sqs") queue_url = "https://sqs.ap-northeast-1.amazonaws.com/xxxxxxxx/test-queue" response = sqs.send_message(QueueUrl=queue_url, MessageBody=json.dumps({"weather": "sunny", "temperature": 32})) print(response)
実行結果は以下のようになります。
{'MD5OfMessageBody': '24a7ffc4a4c761e6f9054c75f933c8f3', 'MessageId': 'a6f5ac1e-da8f-4338-8b14-a38557f9cee9', 'ResponseMetadata': {'RequestId': '3bfd77ab-3837-5377-9088-2bed5d28a434', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '3bfd77ab-3837-5377-9088-2bed5d28a434', 'date': 'Sat, 21 Jan 2023 22:10:39 GMT', 'content-type': 'text/xml', 'content-length': '378'}, 'RetryAttempts': 0}}
メッセージが送信されているか確認します。
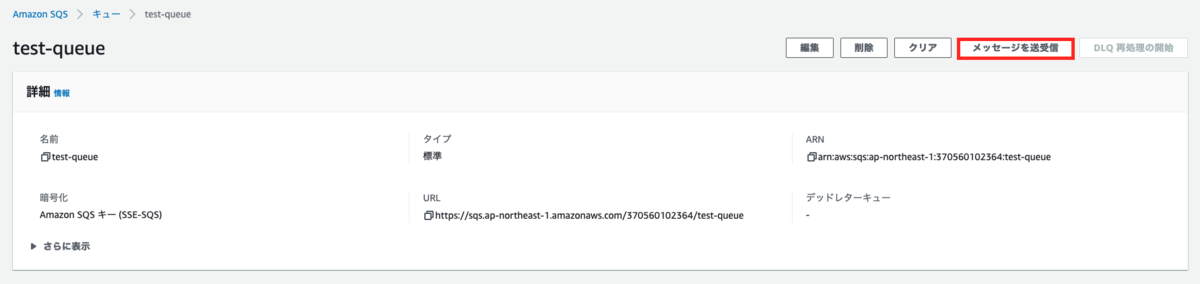
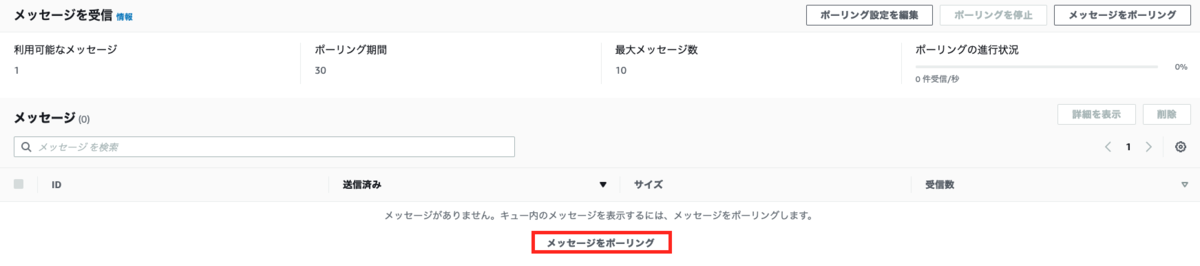

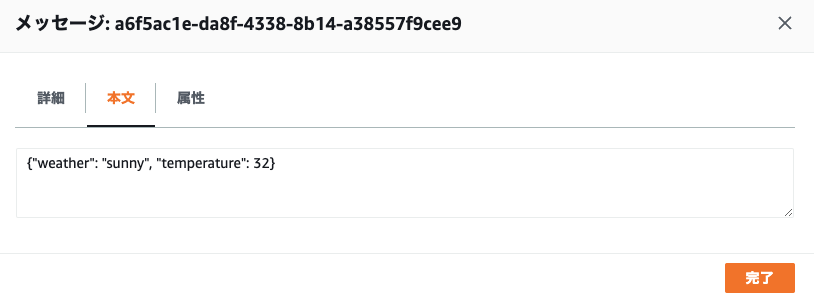
4. EC2 でメッセージを SQS から受信する処理の作成
SQS からメッセージを受信する処理です。受信した後に message.delete() をしないとメッセージはキューに残り続けます。
import boto3 sqs = boto3.client("sqs") queue_url = "https://sqs.ap-northeast-1.amazonaws.com/xxxxxxxx/test-queue" response = sqs.receive_message(QueueUrl=queue_url, MaxNumberOfMessages=1) print(response) for message in response["Messages"]: sqs.delete_message(QueueUrl=queue_url, ReceiptHandle=message["ReceiptHandle"])
実行結果は以下のようになります。送信したメッセージを受信したことがわかります。
{'Messages': [{'MessageId': 'a6f5ac1e-da8f-4338-8b14-a38557f9cee9', 'ReceiptHandle': 'AQEB9wlV11+SyA4VDhX1ne+9Xe+y6tBFeW+7+ySibha5jC9uLECQg/pfXJF3Ez8TMWEeCJt/5Yxzh/Mbhym+3/EO1E1QCJ0gpY569NyBZXEDhVgHGuIX2ZIg9x8l5AL78Qv/r9lDBhSD4qeXeXEQq9Kv7Y9lvFueRHy/bdG1GNKO6dbN7HGaaLt9oEVyWbH2dsHesaxUGJNW8uBd4pQn+kib0ATT4xlcts4ciLnFYgXv6W4HiF8owvJcxqyNkS/gJ3qNcuRoLTeX/7lsLAyjvsLg5pUX4f/bdSTVtvlrn7PyC861vd3x1nlX0G5lN0+ysM2FYaaR7sLgjy+o+tD9T8KtzvRM7Mb+2pUYmudZezSjnWoAftjF4lJbz/Uk80l5zf/HRwIc5GU4Na1HgCIbVACtyA==', 'MD5OfBody': '24a7ffc4a4c761e6f9054c75f933c8f3', 'Body': '{"weather": "sunny", "temperature": 32}'}], 'ResponseMetadata': {'RequestId': 'c3c980fb-b3ef-5283-a91b-dcbddfad4054', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'c3c980fb-b3ef-5283-a91b-dcbddfad4054', 'date': 'Sat, 21 Jan 2023 22:41:06 GMT', 'content-type': 'text/xml', 'content-length': '920'}, 'RetryAttempts': 0}}
さいごに
今回は 単純な構成での連携でしたが、次はファンアウトを使った連携等にも挑戦してみたいと思います。