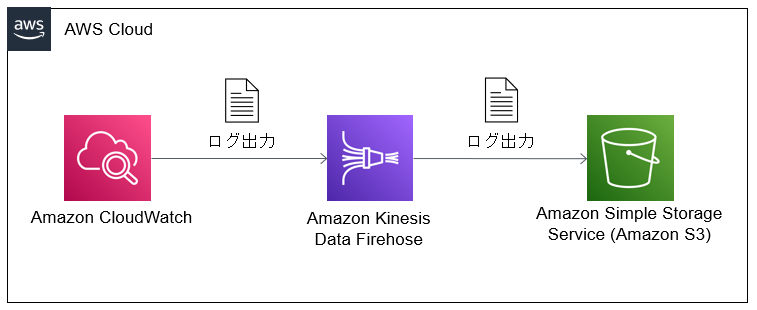
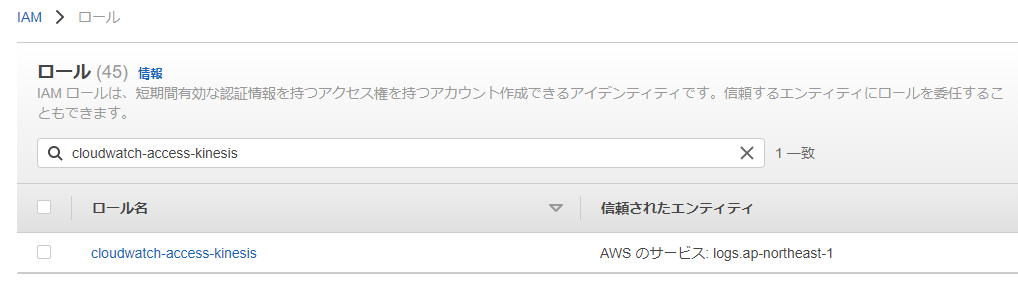
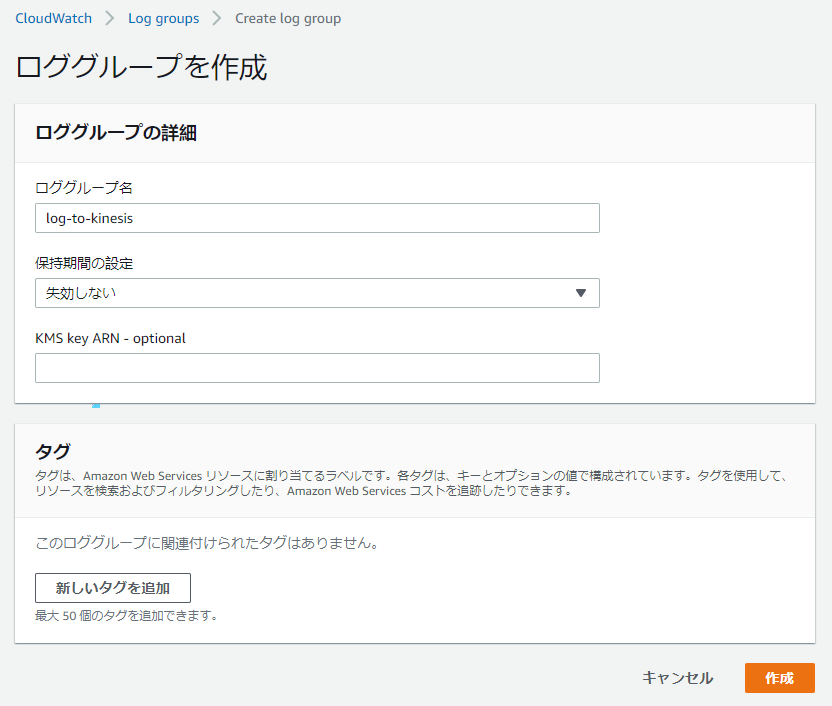
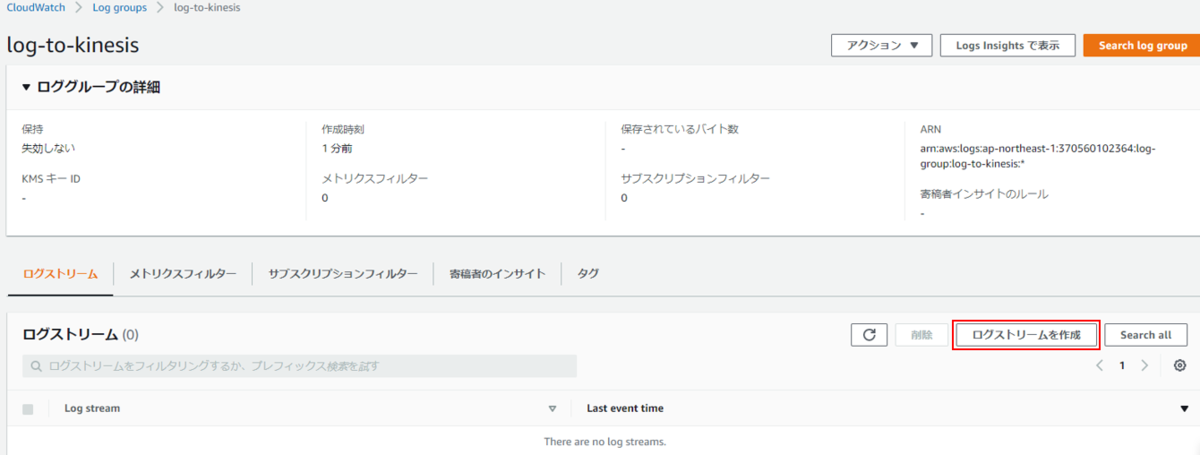
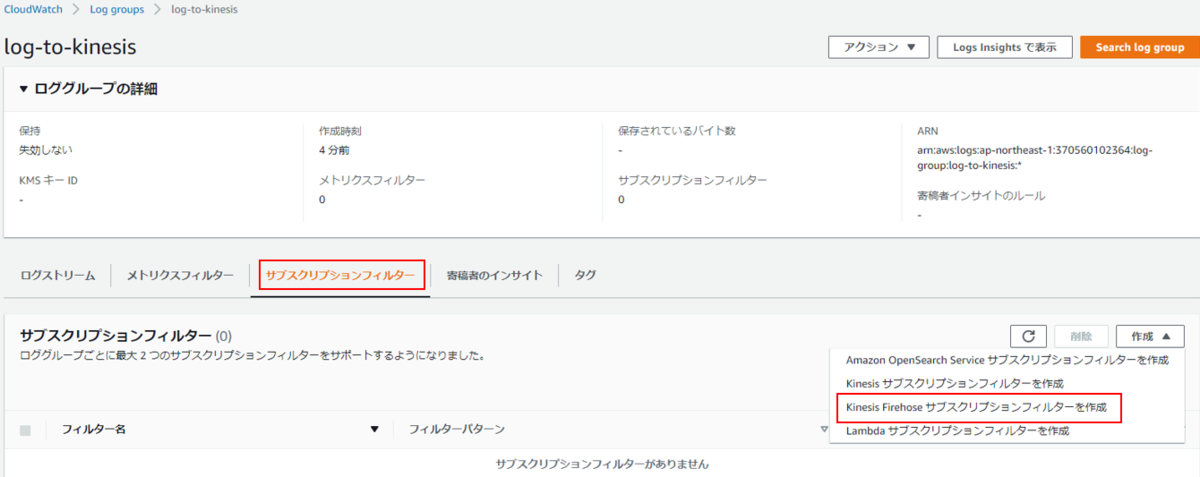
はじめに
マネジメントコンソールで手作業でインフラ環境を構築していくのは、最初は直感的でわかりやすいかと思います。ただ、同じ環境を複数用意する、複数の環境に同じ修正を横展開するといった作業を人力でやり続けることは効率が悪く、設定ミスも発生しやすくなります。今回はそのような時に役立つ CloudFormation を使ってみたいと思います。
使用するサービス
CloudFormation の利用の流れ
- CloudFormation テンプレートを作成する
- テンプレートを適用する
- CloudFormation スタックが作成され、それに紐づく形で AWS リソースが自動構築される

スタックとは
CloudFormation で構築された AWS リソースはスタックという集合にまとめられます。テンプレートを修正し、スタックを指定して再度適用することで、スタック上の AWS リソースの設定を変更したり、リソースを削除することができます。
テンプレートとは
スタックの設計図です。JSON か YAML 形式で記述します。テンプレートに関する詳細はこちらをご参照ください。
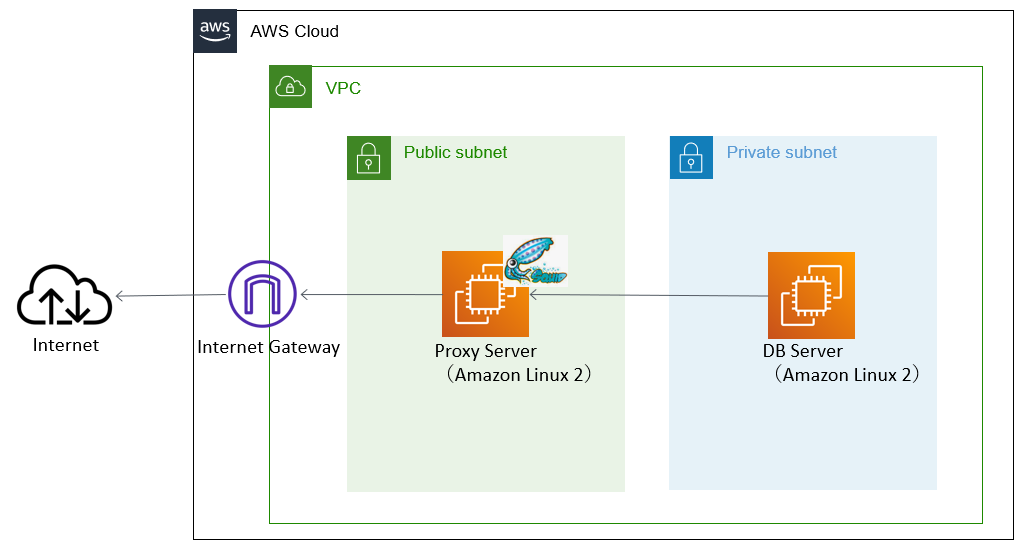
今回のゴール
CloudFormation のテンプレート(yml)を作成し、それを使用して以下のようなインフラ環境を構築する。

作成する AWS リソース
- VPC
- サブネット(パブリック×1、プライベート×1)
- ルートテーブル(パブリック×1、プライベート×1)
- インターネットゲートウェイ
- セキュリティグループ(パブリック×1、プライベート×1)
- EC2(パブリック×1、プライベート×1)
CloudFormation テンプレートの解説
CloudFormation テンプレートはいくつかのセクションに分かれています。本エントリーではよく使われる以下3つのセクションについて説明します。
Resources セクション
構築する AWS リソースの設計を記述するセクション。例えば、VPC の設定は以下のように行います。このテンプレートでは「fjVpc」が VPC リソースを表す論理 ID で、この ID を使ってリソース間の紐づけを行います。
# Resources Section Resources: # VPCの設定 fjVpc: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 EnableDnsHostnames: true EnableDnsSupport: true InstanceTenancy: default Tags: - Key: Name Value: fjVpc
Parameters セクション
実行時に値を選択(入力)するセクション。例えば、以下のようにインスタンスタイプを変数として定義し、実行時に選択する形式にすることができます。
# Parameters Section Parameters: InstanceType: Type: String Default: t2.micro AllowedValues: - t2.micro - t2.small - t2.medium Desctiption: Select EC2 instance type. KeyPair: Description: Select KeyPair Name. Type: AWS::EC2::KeyPair::KeyName
Mappings セクション
変数を Map 形式に定義できるセクション(実行環境によって変わる値を定義するのに用いられることが多い)。例えば、AMI ID はリージョンによって変わるため、以下のように AMI ID を定義します。
# Mappings Section Mappings: RegionMap: us-east-1: hvm: 'ami-a4c7edb2' ap-northeast-1: hvm: 'ami-3bd3c45c'
CloudFormation テンプレートの作成
以下のようなテンプレートを作成しました。
AWSTemplateFormatVersion: "2010-09-09" Description: Network and server resource template # Parameters Section Parameters: InstanceType: Type: String Default: t2.micro AllowedValues: - t2.micro - t2.small - t2.medium Description: Select EC2 instance type. KeyPair: Description: Select KeyPair Name. Type: AWS::EC2::KeyPair::KeyName # Mappings Section Mappings: RegionMap: us-east-1: hvm: 'ami-a4c7edb2' ap-northeast-1: hvm: 'ami-3bd3c45c' # Resources Section Resources: ############### VPC ############### fjVpc: Type: AWS::EC2::VPC Properties: CidrBlock: 10.0.0.0/16 EnableDnsHostnames: true EnableDnsSupport: true InstanceTenancy: default Tags: - Key: Name Value: fjVpc ############### Subnet, RouteTable, IGW ############### ## パブリックサブネット fjSubnetPublic: Type: AWS::EC2::Subnet Properties: CidrBlock: 10.0.0.0/24 VpcId: Ref: fjVpc MapPublicIpOnLaunch: true Tags: - Key: Name Value: fj-subnet-public - Key: Type Value: Public ## プライベートサブネット fjSubnetPrivate: Type: AWS::EC2::Subnet Properties: CidrBlock: 10.0.1.0/24 VpcId: Ref: fjVpc MapPublicIpOnLaunch: false Tags: - Key: Name Value: fj-subnet-private - Key: Type Value: Isolated ## パブリックサブネット用のルートテーブル fjRoutePublic: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: fjVpc Tags: - Key: Name Value: fj-route-public ## パブリックサブネットへルート紐付け fjRoutePublicAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: RouteTableId: Ref: fjRoutePublic SubnetId: Ref: fjSubnetPublic ## パブリックサブネット用ルートテーブルのデフォルトルート fjRoutePublicDefault: Type: AWS::EC2::Route Properties: RouteTableId: Ref: fjRoutePublic DestinationCidrBlock: 0.0.0.0/0 GatewayId: Ref: fjIgw DependsOn: - fjVpcgwAttachment ## プライベートサブネット用のルートテーブル fjRoutePrivate: Type: AWS::EC2::RouteTable Properties: VpcId: Ref: fjVpc Tags: - Key: Name Value: fj-route-private ## プライベートサブネットへルート紐付け fjRoutePrivateAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: RouteTableId: Ref: fjRoutePrivate SubnetId: Ref: fjSubnetPrivate # インターネットへ通信するためのゲートウェイの作成 fjIgw: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: fj-igw fjVpcgwAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: Ref: fjVpc InternetGatewayId: Ref: fjIgw ############### Security groups ############### ## インターネット公開のセキュリティグループの生成 fjSgPublic: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Security group for public GroupName: public SecurityGroupEgress: - CidrIp: 0.0.0.0/0 Description: Allow all outbound traffic by default IpProtocol: "-1" SecurityGroupIngress: - CidrIp: 0.0.0.0/0 Description: from 0.0.0.0/0:80 FromPort: 80 IpProtocol: tcp ToPort: 80 - CidrIp: 0.0.0.0/0 Description: from 0.0.0.0/0:22 FromPort: 22 IpProtocol: tcp ToPort: 22 Tags: - Key: Name Value: fj-sg-public VpcId: Ref: fjVpc ## プライベートサブネットインスタンス用のセキュリティグループの生成 fjSgPrivate: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Security Group of private GroupName: private SecurityGroupEgress: - CidrIp: 0.0.0.0/0 Description: Allow all outbound traffic by default IpProtocol: "-1" SecurityGroupIngress: - CidrIp: 0.0.0.0/0 Description: from 0.0.0.0/0:22 FromPort: 22 IpProtocol: tcp ToPort: 22 - CidrIp: 0.0.0.0/0 Description: from 0.0.0.0/0:22 FromPort: -1 IpProtocol: icmp ToPort: -1 Tags: - Key: Name Value: fj-sg-private VpcId: Ref: fjVpc ############### Server ############### ## EC2(パブリックサブネット) fjEC2Public: Type: AWS::EC2::Instance Properties: ## Mappingsセクションの値をFindMap関数で取得 ImageId: !FindInMap [ RegionMap, !Ref 'AWS::Region', hvm] ## Parametersセクションの値をRef関数で取得 InstanceType: !Ref InstanceType SubnetId: !Ref fjSubnetPublic Tags: - Key: Name Value: fj-ec2-public SecurityGroupIds: - !Ref fjSgPublic KeyName: !Ref KeyPair ## EC2(プライベートサブネット) fjEC2Private: Type: AWS::EC2::Instance Properties: ## Mappingsセクションの値をFindMap関数で取得 ImageId: !FindInMap [ RegionMap, !Ref 'AWS::Region', hvm] ## Parametersセクションの値をRef関数で取得 InstanceType: !Ref InstanceType SubnetId: !Ref fjSubnetPrivate Tags: - Key: Name Value: fj-ec2-private SecurityGroupIds: - !Ref fjSgPrivate KeyName: !Ref KeyPair
CloudFormation スタックの作成
作成した CloudFormation テンプレートを使用して CloudFormation スタックを作成します。

Parameters セクションで設定した項目に対して値を入力します。この後はすべてデフォルト設定でOKです。

スタックが作成されました。

AWS リソースの確認
以下のように AWS リソースが作成されていることが確認できました。
VPC

サブネット

ルートテーブル

インターネットゲートウェイ

セキュリティグループ

EC2

動作確認
EC2 の動作確認を行います。
パブリックサブネット用の EC2
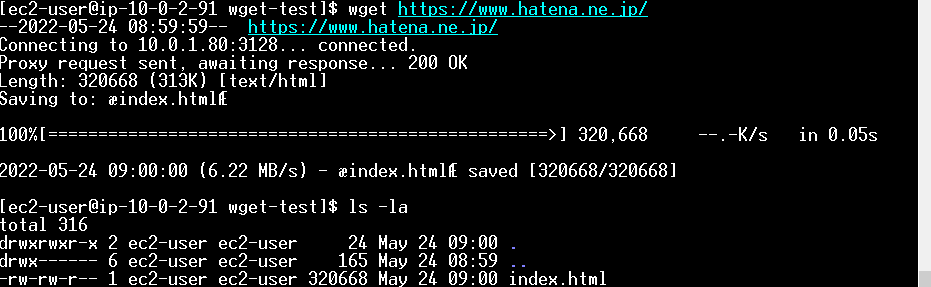
SSH で EC2 にログインします。

EC2 へのログインを確認しました。

プライベートサブネット用の EC2
パブリックサブネット用の EC2 から SSH で プライベートサブネット用の EC2 へのログインをすることができました。

また、ping も通ることがわかりました。

さいごに
CloudFormation テンプレートを実際に作成したのは今回が初めてでした。ただ、AWS のネットワークやサーバー構築に関して基本的な知識があればすぐに理解できると感じました(AWS に関する基本的な理解がない場合はかなり厳しそう)。今回はシンプルな構成のインフラ環境でしたが、次は少し複雑な環境構築にも挑戦してみようと思います。